
Why this matters now: As AI systems move from research labs into production—powering medical diagnoses, financial decisions, and autonomous systems—the question is no longer "does it work?" but "can we trust it?" This article distills years of research into practical frameworks that practitioners can use to build more reliable, robust, and trustworthy machine learning systems.
The Wake-Up Call
Let me start with a story from my PhD days at CMU. I was at a conference poster session when I encountered a researcher presenting work on using LSTMs for gene expression prediction. The results showed improvement over SVMs—unsurprising given that RNNs were already known to dominate sequence data tasks.
Perhaps too boldly, I asked: "What's remarkable about simply applying an existing technique?"
Her response was refreshingly honest: "Nothing remarkable. Real innovation is for people who get into CMU. I can't do that—I just need to publish papers, graduate, and get a job."
This was the first time I truly grasped that not everyone pursues the same goals in research. While working at prestigious institutions with renowned advisors had shaped my view that research should meet the highest standards of innovation, the reality is far more nuanced. People have different starting points, experiences, constraints, and aspirations.
That conversation taught me to stop judging others' work by my standards alone. We're all on different journeys.
Why Trustworthy ML Matters for Production Systems
When ResNet-100 emerged in 2016-17, I voiced a concern that few seemed to share at the time: such massive architectures shouldn't be evaluated solely on accuracy. There was no evidence that state-of-the-art accuracy came from learning genuinely useful patterns rather than dataset confounding factors. For models of that scale, ImageNet seemed relatively small, making the presence of spurious correlations far more likely. Back then, I didn't realize these concerns could form the basis of publishable research.
Fast forward to today's large models—DALL-E, ChatGPT, Stable Diffusion, SAM—and I tell my students the same thing: don't be dazzled by apparent magic. Much of the impression comes from users not yet being accustomed to these models' limitations. Just as ResNet-100 initially seemed to herald a new era of solved computer vision, these models will reveal their trustworthiness challenges as they become integrated into daily workflows.
The Pattern: Revolutionary models excel at their initial benchmarks, but real-world deployment exposes critical gaps in robustness, fairness, interpretability, and security. As we move from "impressive demos" to "mission-critical systems," trustworthy ML becomes non-negotiable.
What Is Trustworthy Machine Learning?
Trustworthy ML is an umbrella term covering several critical subfields. While the exact boundaries remain fluid, the core areas include:
Robustness
This encompasses domain adaptation, domain generalization, and related areas. The central challenge: machine learning models are typically tested on data that differs from training data. How do we ensure these distribution shifts don't degrade performance? When your model trained on sunny-day images encounters rainy conditions, will it still work?
Adversarial Robustness (Security)
Made famous by the adversarial panda image, this field examines whether models maintain performance when facing carefully crafted, imperceptible perturbations. These aren't random noise—they're precisely calculated modifications designed to fool your model. In production, this matters for everything from autonomous vehicles to fraud detection systems.
Interpretability
Can we explain how and why a model makes its decisions? For medical diagnoses, loan approvals, and criminal justice applications, "the model said so" isn't acceptable. Stakeholders need to understand the reasoning process.
Fairness
Models shouldn't rely on sensitive attributes (gender, age, race, socioeconomic background) when making decisions. Additionally, minority groups often get systematically filtered out during data collection—a statistical artifact that perpetuates inequity. Your model's bias isn't just an ethics problem; it's a legal and business risk.
Critical Insight: Trustworthiness is inherently subjective. A model interpretable to a radiologist may be opaque to a patient. Equal admission rates across regions versus standardized national testing—which is "fair"? Machine learning research doesn't define what "trustworthy" means; it provides tools to implement whatever definition stakeholders choose. This subjectivity is a feature, not a bug.
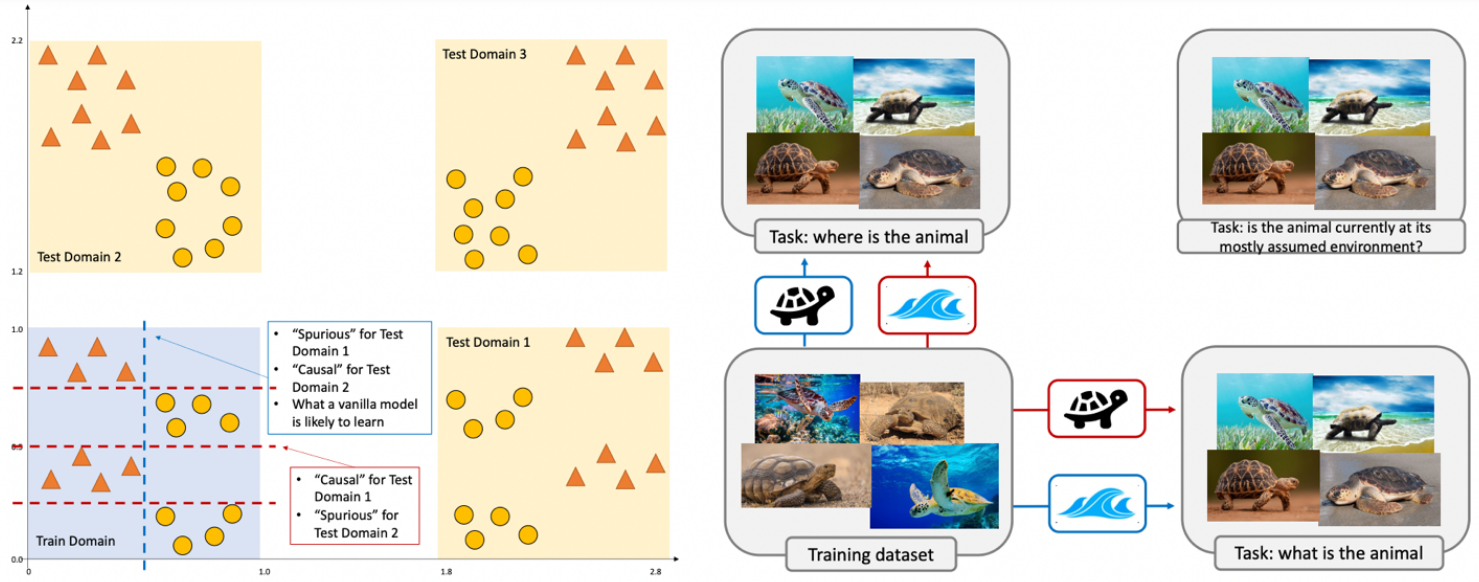
Figure 1: The Subjectivity of Trustworthiness
Consider sea turtles, which are highly correlated with ocean environments. If we're predicting animals, the turtle is the "semantic" signal and ocean is "spurious." But if we're predicting environments, the ocean becomes semantic and the turtle becomes spurious. The mathematical frameworks for trustworthy ML are universal, but what counts as "trustworthy" depends entirely on your task and stakeholders.
The Core Challenge: Data Quality
Building trustworthy ML models is difficult for many reasons, but the primary culprit is the data itself. This is also why data-centric AI has gained such prominence in recent years.
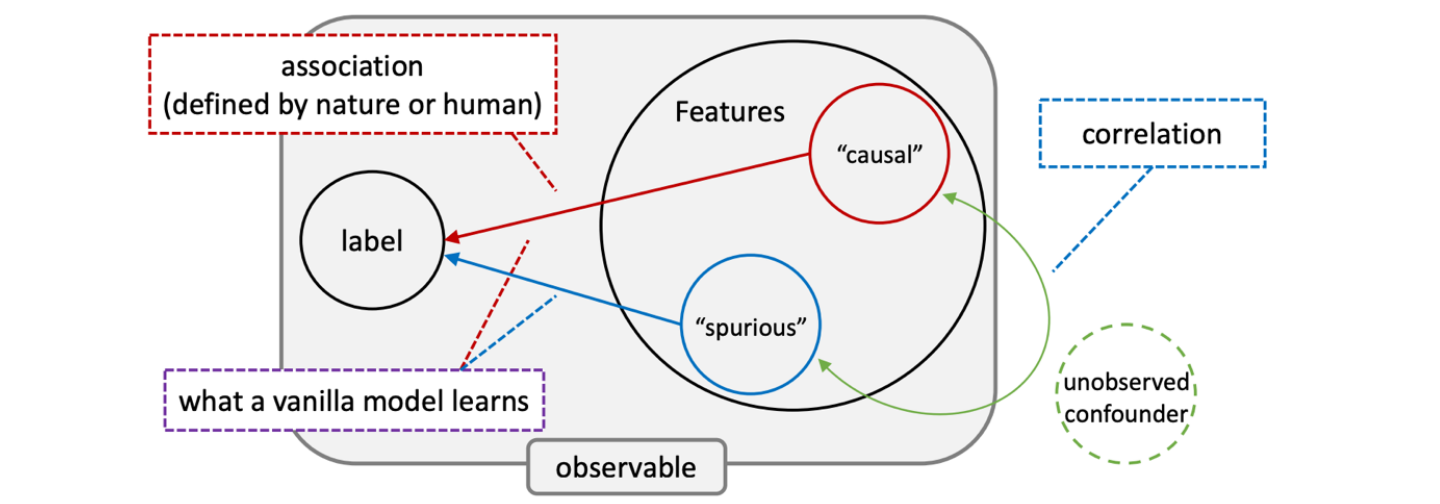
Figure 2: The Data Quality Problem
Historical data is riddled with spurious correlations and biases. Modern deep learning achieves miracles by learning from massive datasets—but this very strength becomes a weakness when datasets contain systematic confounding factors. The model learns what's in the data, not necessarily what's useful for the task.
This fundamental challenge explains why trustworthy ML problems persist across domains. Your model isn't broken—it's doing exactly what you trained it to do: find patterns in data. The problem is that real-world data contains patterns we don't want the model to learn.
Three Universal Frameworks for Trustworthy ML
Through extensive research (summarized in our comprehensive survey paper[1]), we've identified that the vast majority of trustworthy ML methods—across robustness, fairness, adversarial defense, and even interpretability—derive from three fundamental paradigms.
Framework 1: Domain-Adversarial Methods (DANN-style)
The Core Idea: Train models that cannot distinguish between different domains or sensitive attributes.
The Mechanism: For domain adaptation, imagine you want a model to recognize animals in both photographs and sketches. The intuitive approach: ensure the model learns no domain-specific features (can't tell if an image is a photo or sketch).
How do you prevent a model from distinguishing photos from sketches? First, consider how you'd enable this distinction: train a domain classifier using domain labels. Now, conceptually divide your deep learning model at any layer into an encoder (before the cut) and decoder (after the cut). The layer's output becomes the representation.
Use the domain classifier as a decoder. To make it fail at domain classification while keeping it fixed, modify the encoder to produce representations the classifier cannot discriminate. Meanwhile, maintain a standard classifier for your actual task (recognizing cats, dogs, giraffes, elephants).
This is Domain-Adversarial Neural Network (DANN)[4].
Applications Beyond Robustness:
- Replace "domain" with "sensitive attribute" → fairness methods
- Extend from two domains to multiple → domain generalization
- Use specialized architectures (texture-only, patch-based, weak classifiers) instead of trained domain classifiers
Our survey documents hundreds of papers following this framework across trustworthy ML subfields. The mathematical core remains unchanged; only the specific instantiation varies.
Framework 2: Worst-Case Data Augmentation + Regularization
The Core Idea: Instead of random data augmentation, select augmentations that maximize training difficulty, forcing the model to learn robust features.
Why It Works: Data augmentation is one of the simplest ways to improve model performance. In trustworthy ML, the most effective variant is worst-case augmentation: for each sample, choose the transformation that makes the loss highest rather than random transformations.
Implementation Approaches:
Direct worst-case selection: For standard augmentations (rotation, flipping, frequency domain modifications), replace random selection with gradient-based or forward-pass selection of the hardest case. This guarantees at least equivalent performance to random augmentation and typically improves convergence speed. The tradeoff: computational cost of selecting the worst case.
Generative model integration: Connect a GAN, VAE, or diffusion model to your training pipeline. These naturally enable gradient-based worst-case selection. As generative models improve, this approach scales automatically. The challenge: ensuring generated data doesn't drift too far from the original (maintaining label validity).
Representation-level augmentation: Our RSC (Representation Self-Challenging) method[6] applies worst-case augmentation at the representation level (between encoder and decoder) rather than input level. This simple approach achieved state-of-the-art results on domain generalization benchmarks and performed well on biological datasets.
Adding Regularization: When augmentation creates multiple copies of each sample, regularization can leverage these pairs/groups effectively. Common approach: enforce consistency across augmented versions—the model should extract shared features while ignoring augmentation-specific variations.
The space here is vast: any distance metric yields a potential regularization method. Different augmentations × different metrics × different applications creates near-infinite variations. Our work[7] provides a systematic framework for this family of methods.
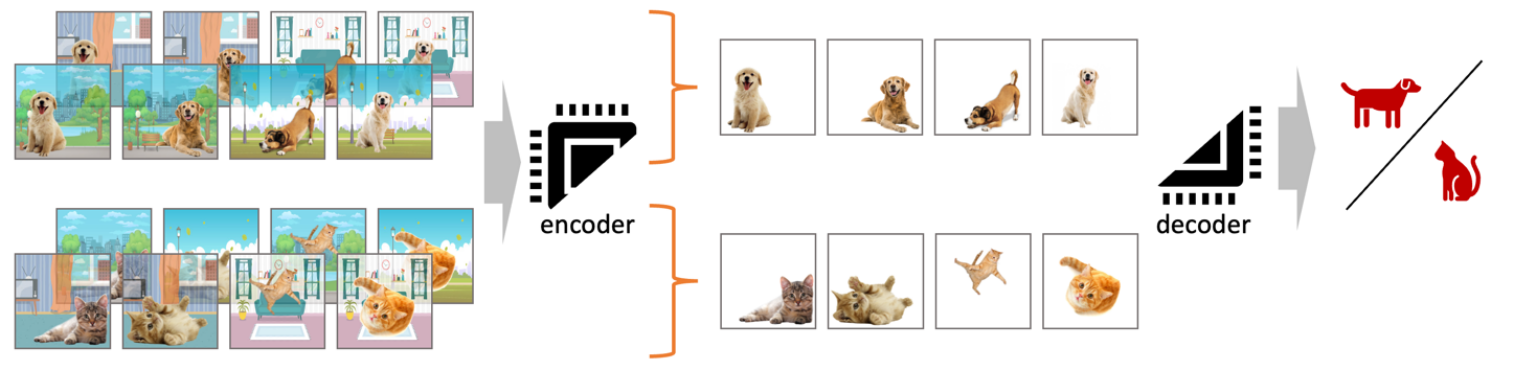
Figure 3: Augmentation + Regularization Synergy
Consider a cat-dog classifier. Training data shows cats predominantly indoors and dogs outdoors. The model might learn "indoor vs. outdoor" rather than actual animal features. Data augmentation creates indoor dogs and outdoor cats. Regularization pushes the model to find commonalities in each pair, ignoring backgrounds. This combination teaches the model to focus on the animals themselves.
Framework 3: Sample Reweighting
The Core Idea: Give under-represented or difficult samples more weight during training.
This family is conceptually straightforward but remarkably effective. In many robustness and fairness tasks, certain samples belong to minority groups that models easily overlook. The intuitive solution: weight these samples more heavily during training.
Evolution of Methods:
- Early approaches: higher loss → higher weight (model focuses on difficult samples)
- Modern variants: sophisticated weight estimation schemes
- Extreme (hypothetical): using another deep learning model to estimate weights
While sample reweighting has been fundamental to machine learning since weighted least squares, its importance in deep learning was initially overlooked. As real-world applications revealed pervasive under-representation issues, the community rediscovered these methods' value.
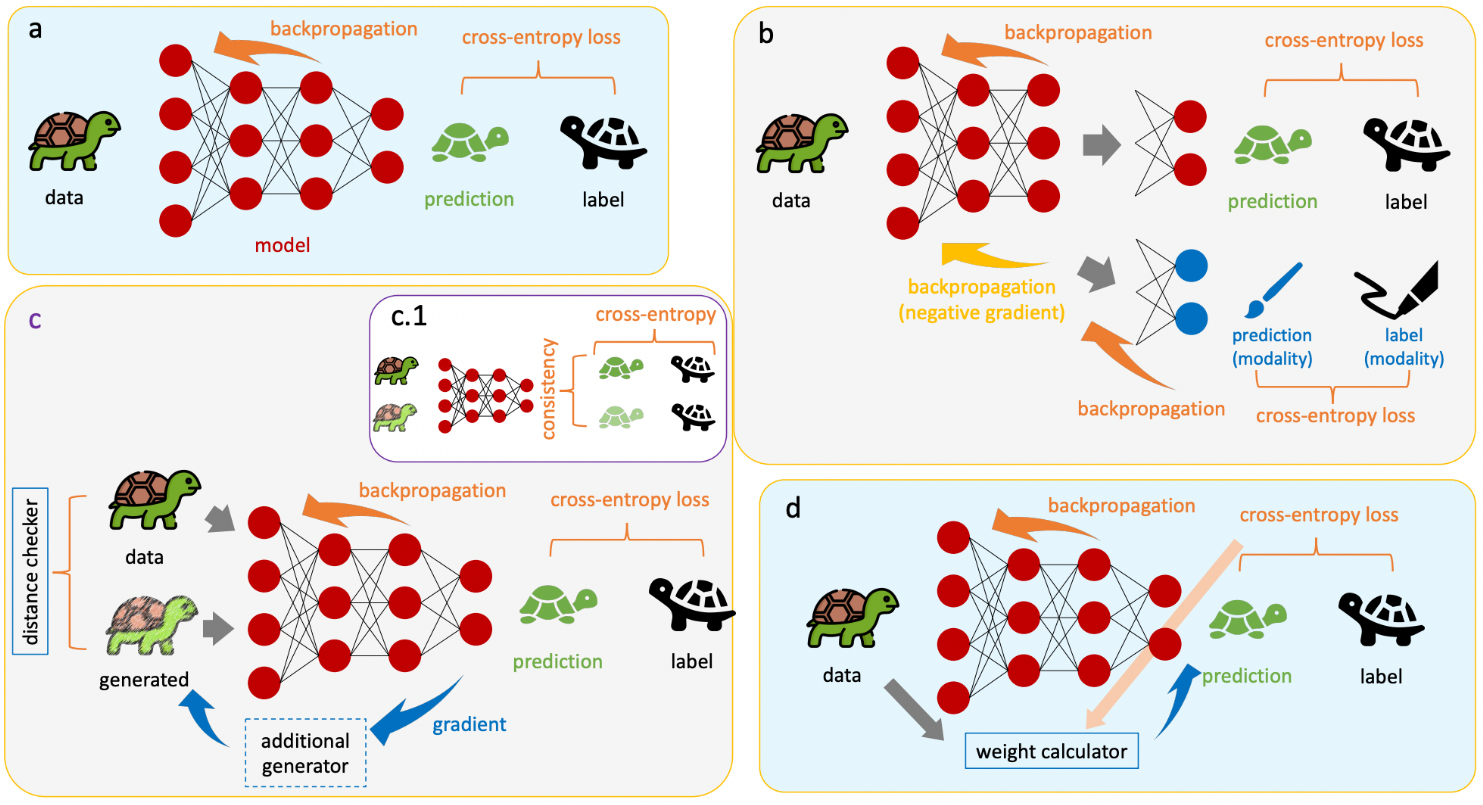
Figure 4: Three Frameworks Overview
(a) ERM baseline: standard empirical risk minimization. (b) DANN-style extension: adversarial training to remove unwanted features. (c) Augmentation extension, with (c.1) showing added regularization. (d) Sample reweighting extension. These three paradigms (red) connect ERM baseline (orange) to various trustworthy ML domains (blue).
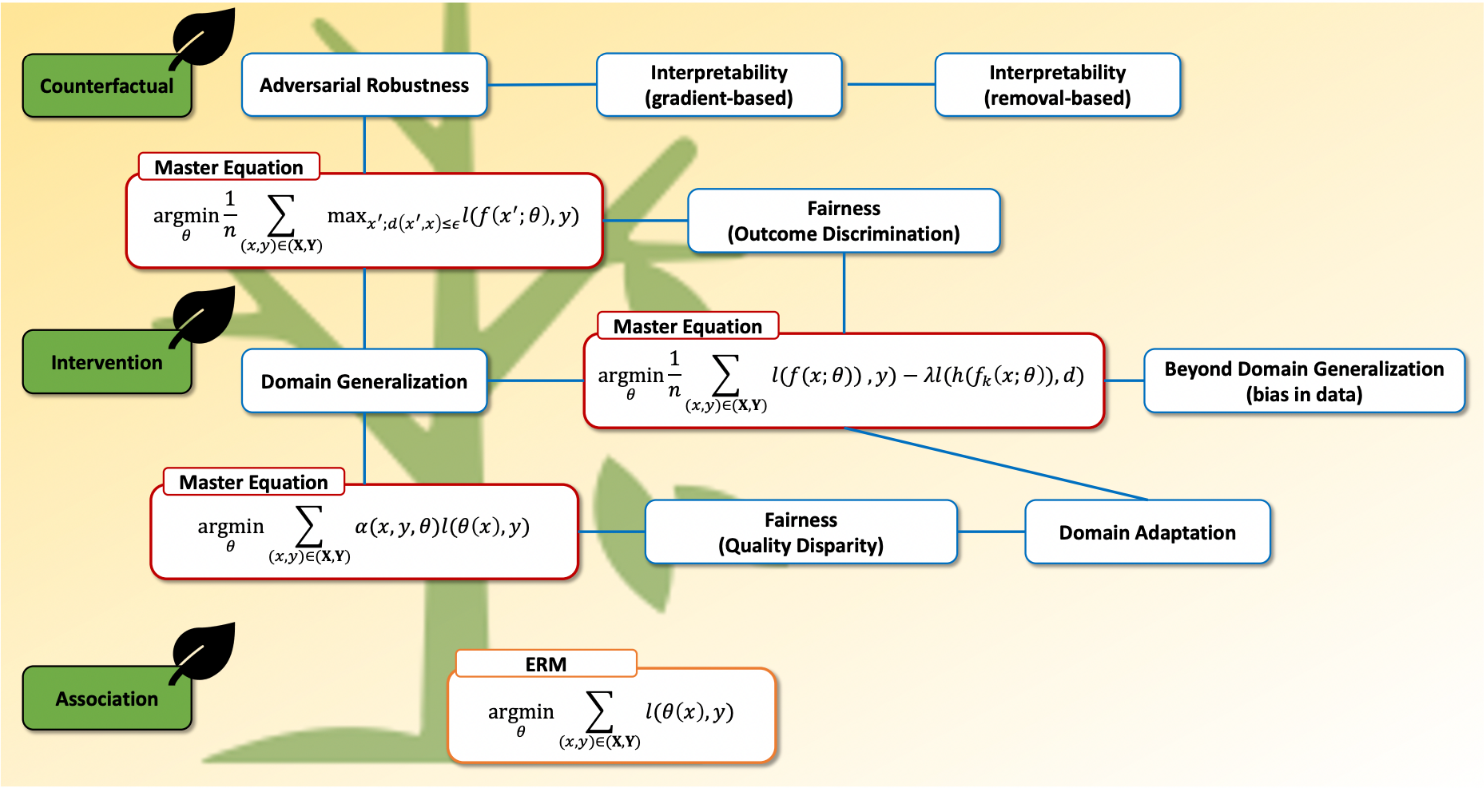
Figure 5: Mathematical Connections
This diagram illustrates how the three paradigms (red) mathematically connect the ERM baseline (orange) to specific domains (blue): robustness, fairness, adversarial robustness, and interpretability. For deeper mathematical relationships, see our full survey[1].
From Research to Practice: Your Roadmap
Applying Frameworks to Modern Large Models
One of the most exciting findings from our survey work: these frameworks seamlessly extend to the large model era. The key is recognizing that prompt tuning, adapters, and fine-tuning can all be expressed within the ERM framework.
Fine-tuning: Treat the pre-trained model as initialization. Mathematically identical to standard ERM with different starting parameters.
Adapters: Insert new weights and train only those parameters. Still ERM, just with selective parameter updates.
Soft Prompts: View prompt generation as an encoder feeding into the large model (decoder). The complete system is an encoder-decoder architecture.
Once you see this equivalence, the path forward is clear: classic trustworthy ML methods that worked in traditional settings will work with large models. You just need to adapt them to the new architecture.
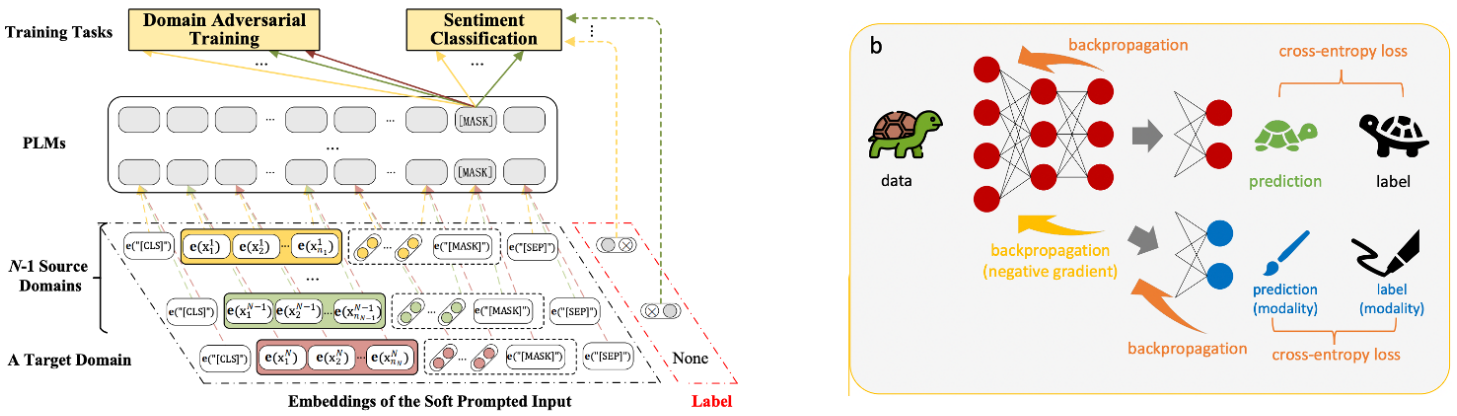
Figure 6: DANN in the Large Model Era
Example from "Adversarial soft prompt tuning for cross-domain sentiment analysis." The domain adversarial training component directly parallels traditional DANN, adapted for prompt-based learning. The core mathematical framework remains unchanged.
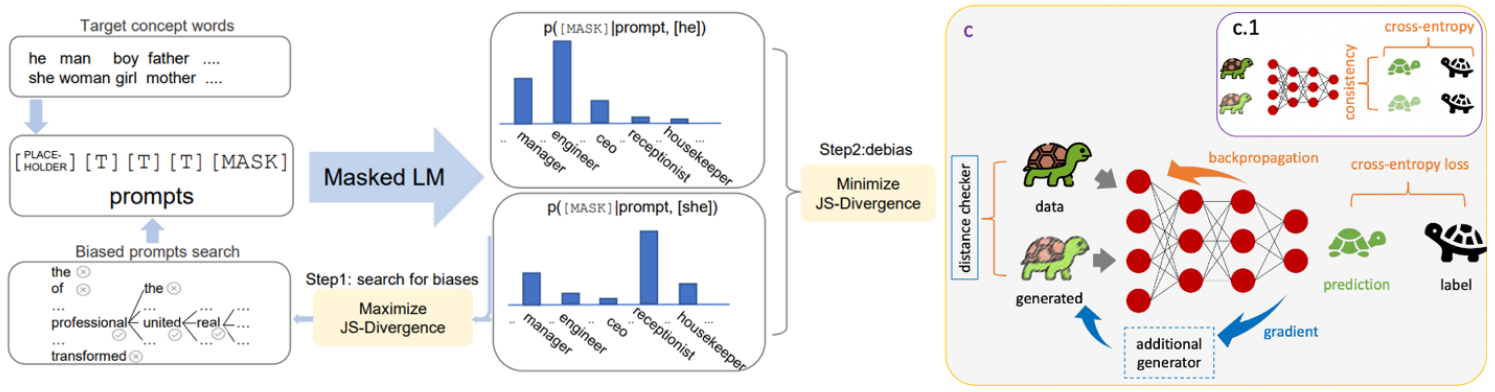
Figure 7: Augmentation + Regularization for Large Models
Example from "Auto-debias: Debiasing masked language models with automated biased prompts." The method identifies biased prompts and uses consistency loss to remove bias—a direct application of the augmentation + regularization paradigm to language models.
Combining Frameworks for Better Performance
An especially effective strategy: combine methods from different paradigms. Since the frameworks address different aspects of trustworthiness, their combination often yields synergistic improvements.
In our theoretical work[2], we experimented with combining basic domain classifiers and simple data augmentation. Even this minimal combination improved performance. Since we used the simplest methods from each paradigm, more sophisticated combinations should yield even better results.
Our W2D Method: This work combined two worst-case concepts:
- Feature dimension: drop the most predictive features (data augmentation paradigm, building on our RSC work)
- Sample dimension: reweight based on loss (reweighting paradigm)
We call this "Worst-case in Two Dimensions" (W2D)[8]. The method is elegant, intuitive, and highly effective. Yet we only used relatively simple instantiations from each paradigm—suggesting substantial room for improvement by incorporating more sophisticated methods.
Quick Wins for Practitioners
If developing novel methods seems daunting, applying existing frameworks to new applications can be highly effective. Here are two approaches that consistently deliver results:
W2D for Domain Shift Problems: When we recommend W2D to researchers less focused on algorithmic frontiers, they often achieve immediate SOTA improvements. We've seen this repeatedly on drug-related datasets. W2D's power comes from pure statistical principles rather than subjective regularization, giving it broad applicability. Since it requires only cross-entropy loss, it plugs into virtually any model architecture.
Note: W2D struggled with cellular image segmentation, likely because segmentation losses don't fit the framework as naturally. Method-problem alignment matters enormously.
AlignReg for General Robustness: This method is remarkably simple yet effective. When high school students approach me for research collaboration, I often suggest they try AlignReg—it almost invariably improves performance. They sometimes say "machine learning is so easy!" Not quite—it took substantial work to distill the approach to this level of simplicity.
The Key: Don't randomly combine methods and applications. Success requires understanding whether your problem's structure matches the method's assumptions. W2D works on cross-domain problems. AlignReg works when you can meaningfully augment data. Match the tool to the task.
Generating Innovation: Beyond 1000 Ideas
The title promises 1000 ideas for trustworthy ML innovation. Have I delivered? I believe so—and if you've followed every point closely, you'll realize it's far more than 1000. If that doesn't resonate yet, I encourage you to read our complete survey[1], which contains much richer detail.
Here's how to generate endless variations:
Within Single Frameworks
DANN-style methods:
- Upgrade the domain classifier with modern techniques (dropout, normalization variants, attention mechanisms, adversarial training)
- Design specialized architectures that learn specific feature types
- Port successful domain adaptation methods to fairness problems (and vice versa)
- Extend two-domain to multi-domain settings
Data augmentation methods:
- Convert any IID augmentation to worst-case (guarantees ≥ baseline performance)
- Pair any augmentation with any distance metric for regularization
- Integrate progressively better generative models (GAN → VAE → diffusion → future models)
- Experiment with augmentation at different representation levels
Sample reweighting:
- Develop sophisticated weight estimation schemes
- Explore different loss-to-weight transformations
- Combine reweighting with other paradigms
Across Frameworks
Any method from paradigm A × any method from paradigm B = potential publication. Since the paradigms address orthogonal aspects of trustworthiness, combinations frequently work. The space of (DANN variants × augmentation variants × reweighting variants) is enormous.
In Large Model Settings
Take any classic method that proved effective in traditional settings and adapt it to:
- Prompt tuning frameworks
- Adapter-based approaches
- Fine-tuning strategies
- Novel large model architectures as they emerge
In New Application Domains
Every time a new application domain emerges or gains importance:
- Test whether existing methods transfer
- Identify domain-specific challenges requiring method adaptation
- Combine proven methods in ways appropriate to domain constraints
The combinations of (methods × large model variants × application domains × evaluation settings) generate far more than 1000 potential directions.
Who Should Use These Ideas?
I want to be transparent about the audience for these approaches. These ideas primarily help researchers who need publications for career advancement—similar to the PhD student I met years ago who frankly acknowledged her goals.
For practitioners building production systems, these methods provide battle-tested frameworks to improve robustness, fairness, and reliability. Choose based on your specific failure modes and constraints.
For researchers pursuing fundamental breakthroughs, these systematic variations may feel incremental. Truly era-defining ideas are rare. Those are what I hope to pursue in my own lab. But even fundamental researchers benefit from understanding these frameworks—they reveal the deep mathematical structures underlying surface-level diversity.
A Personal Note on Research Philosophy
Some might wonder: "Won't sharing these ideas reduce your potential publications?"
By my current understanding, what matters isn't paper quantity but the depth of insight behind them. Without that substance, papers are just decorative moves that crumble under scrutiny. Of course, I'm still early in my career—these views may evolve with experience.
What I do know: I'm far more interested in working with excellent people on meaningful problems than in hoarding incremental ideas. Excellence isn't limited to résumé credentials—it includes intellectual maturity, research taste, and clarity of purpose.
Key Reference
[1] Liu, H., Chaudhary, M. and Wang, H., 2023. Towards Trustworthy and Aligned Machine Learning: A Data-centric Survey with Causality Perspectives. arXiv preprint arXiv:2307.16851.
[2] Wang, H., Huang, Z., Zhang, H., Lee, Y.J. and Xing, E.P., 2022, August. Toward learning human-aligned cross-domain robust models by countering misaligned features. In Uncertainty in Artificial Intelligence (pp. 2075-2084). PMLR.
[3] Wang, H., Wu, X., Huang, Z. and Xing, E.P., 2020. High-frequency component helps explain the generalization of convolutional neural networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 8684-8694).
[4] Ganin, Y., Ustinova, E., Ajakan, H., Germain, P., Larochelle, H., Laviolette, F., Marchand, M. and Lempitsky, V., 2016. Domain-adversarial training of neural networks. The journal of machine learning research, 17(1), pp.2096-2030.
[5] Madry, A., Makelov, A., Schmidt, L., Tsipras, D. and Vladu, A., 2017. Towards deep learning models resistant to adversarial attacks. arXiv preprint arXiv:1706.06083.
[6] Huang, Z., Wang, H., Xing, E.P. and Huang, D., 2020. Self-challenging improves cross-domain generalization. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part II 16 (pp. 124-140). Springer International Publishing.
[7] Wang, H., Huang, Z., Wu, X. and Xing, E., 2022, August. Toward learning robust and invariant representations with alignment regularization and data augmentation. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (pp. 1846-1856).
[8] Huang, Z., Wang, H., Huang, D., Lee, Y.J. and Xing, E.P., 2022. The two dimensions of worst-case training and their integrated effect for out-of-domain generalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 9631-9641).